Når maskiner lærer fordommer
Utviklingen av kunstig intelligens skjer raskere enn lovene som kan regulere den. På grunn av måten maskiner lærer på, er minoriteter i samfunnet spesielt utsatt. Vi må begynne å snakke om minoritetsvern i forhold til kunstig intelligens i norsk sammenheng – før det er for sent.
Av Mina Young Pedersen
Livene våre preges allerede daglig av kunstig intelligens. Vi bruker spamfiltre for e-post og ansiktsgjenkjenning til å låse opp telefonen. Også norsk byråkrati har begynt å ta i bruk algoritmer til å sortere søknader og gi forslag om skattekriminalitet. Det er all grunn til å tro at det norske fremtidssamfunnet vil ta i bruk flere selvstyrte algoritmer i tiden som kommer. Med makt følger ansvar. Er det grunn til å frykte at spesielt minoriteter i Norge burde være redde for algoritmer og kunstig intelligens?
Etikk for kunstig intelligens har rukket å bli et etablert fagfelt de siste årene. Problemstillingene fagområdet står overfor er mangfoldige. Ett viktig aspekt av KI-etikk er forskning som handler om å programmere en kunstig intelligens til å oppføre seg etisk. Selvkjørende biler må for eksempel komme med en protokoll for hvordan de skal oppføre seg i en faresituasjon: hva skal bilen gjøre i valget mellom å kjøre over en fotgjenger eller inn i en fjellvegg? Det første alternativet redder antageligvis bilførerens liv, mens det andre redder fotgjengerens. Tilfeller som i dag avgjøres av omstendigheter og raske avgjørelser, må i selvkjørende biler være ferdig programmert.
Andre etiske problemstillinger oppstår i forhold til vern av privatliv der en maskin erstatter et menneske i en spesifikk tjeneste. Virtuelle KI-assistenter som Amazons Alexa, Apples Siri og Google Home tar opp og registrerer stemmen din og informasjonen du gir dem. Det er lett å se for seg at stemmegjenkjenning også blir satt i det offentlige rom i fremtiden, for eksempel ved kjøp av bussbilletter, eller pakkehenting hos Posten. Hva skal da gjøres med dataene om din personlige stemme? Slike spørsmål om vern av privatliv er ekstra viktige å stille når kunstig intelligens går fra private produkter til offentlig arena.
Et tredje problem som har oppstått i bruk av kunstig intelligens, er at noen algoritmer viderefører fordommer og diskriminerer minoriteter. Dette gjelder spesielt maskinlæringsalgoritmer og såkalte nevrale nettverk. For å forstå hvordan dette kan gå an, skal vi først se kort på hvordan en maskinlæringsalgoritme fungerer.
En maskin lærer ikke som oss
Maskinlæring er et fagområde innenfor kunstig intelligens som handler om hvordan vi kan programmere en algoritme til å lære av erfaring og forbedre seg på egenhånd. En algoritme kan i denne sammenhengen sees på som en oppskrift, eller liste med instruksjoner, som en datamaskin skal følge.
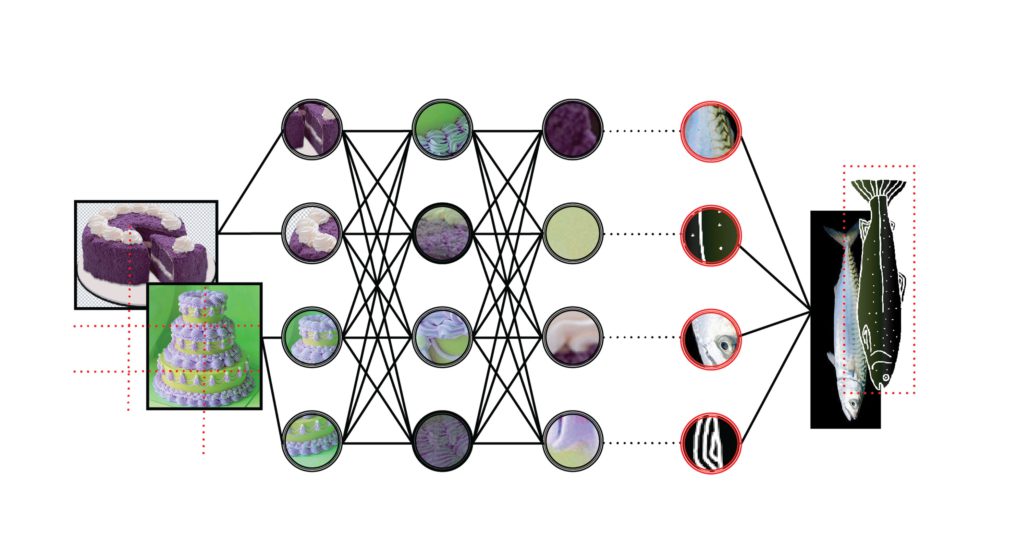
Den mest brukte metoden innenfor maskinlæring i dag er en mengde algoritmer som kalles nevrale nettverk. Nevrale nettverk består av flere lag med rader av simulerte nevroner, også kalt units, inspirert av hvordan nevroner i hjernen behandler informasjon. Gitt en bestemt input, som for eksempel et bilde av en sykkel, gir det nevrale nettverket fra seg en output, for eksempel informasjon som betyr at «dette er et bilde av en sykkel». Et bilde blir gjerne delt opp i piksler, der hver piksel blir en input-del for units i første del av nettverket. Veldig enkelt forklart legger en unit sammen informasjon den får tilsendt og sender ny informasjon basert på den gamle videre til units i neste lag. I hvert steg i nettverket tillegges hver enkel informasjonsdel et tall, også kalt en vekt, som tilsier hvor viktig informasjonen er, og hvor mye plass den bør få i neste runde.
«På verdensbasis har maskinlæring blitt brukt i ansettelsesprosesser, og til å anbefale politiet hvem de bør ransake.»
Men hvordan kan det nevrale nettverket skjønne at nettopp bildet av en sykkel er et bilde av en sykkel? Det er her læringen i maskinlæring kommer inn. Et nevralt nettverk er nemlig trent opp på gitt informasjon. Dette er ofte en stor mengde merket data, det vil si for eksempel massevis av bilder av alle slags ting, der alle bildene med sykler på er merket «sykkel». Denne merkingen er gjort av mennesker på forhånd. Det nevrale nettverket tar et slikt datasett og redigerer sine egne vekter på alle mulige steder inn i nettverket, slik at endelig output skal passe med merkingen av datasettet. Idéen er at neste gang nettverket blir presentert med et bilde av en sykkel, skal det nå ha et slikt oppsett at det kan kjenne igjen sykkelen på bildet.
Dyp læring er opplæring av en type nevrale nettverk hvor det er mer enn ett lag med units mellom input og output. Det positive med dyp læring er at det ofte fungerer veldig bra. Googles omvendte bildesøk og Google Translate er gode eksempler på teknologi som ikke hadde vært på langt nær så bra uten bruk av dyp læring. Men dyp læring har også en bakside. Fordi nevrale nettverk i bruk vanligvis er så utrolig store, er det nesten umulig å spore tilbake til hva som skjer i læringsprosessen når nettverket redigerer vekter. Et vanlig nevralt nettverk utfører over én milliard matematiske operasjoner. Derfor er det veldig vanskelig å vite hvilke sammenhenger nettverket finner mellom input og output: akkurat hvorfor det nevrale nettverket bestemmer at bildet av en sykkel er en sykkel. I flere bildegjenkjenningsalgoritmer har man senere funnet ut at klassifiseringen ble gjort basert på helt andre faktorer enn det vi mennesker ville gjenkjent på et bilde, som hvorvidt bakgrunnen på bildet var uskarpt eller ikke.
At en maskin har problemer med å forklare seg er utrolig viktig å huske på før vi tar i bruk maskinlæringsteknologi, spesielt i tjenester som kontrollerer en ressurs, eller som setter maskinen i en maktposisjon. Norske banker bruker allerede maskinlæring til blant annet å avdekke hvitvasking og i vurdering av søknader om lån. På verdensbasis har maskinlæring blitt brukt i ansettelsesprosesser, og til å anbefale politiet hvem de bør ransake. Får du avslag på lån i banken av en dyplært maskin, er det, på grunn av teknologien den er bygget på, utrolig vanskelig å finne ut av hvorfor.
Datasett med få minoriteter
Minoriteter i samfunnet er generelt underrepresentert både i datasett og i bransjen som utvikler kunstig intelligens. Dette får konsekvenser. En av dem er at tjenester som er laget for bruk av alle grupper i samfunnet fungerer bedre for majoriteten i datasettene, som oftest hvite vestlige menn. Det er flere eksempler på dette i forhold til ansiktsgjenkjenning.
Da dataingeniør og digital aktivist Joy Buolamwini jobbet med ansiktsgjenkjenningsteknologi på Massachusetts Institute of Technology (MIT) i 2015, oppdaget hun at teknologien fungerte vesentlig dårligere på mørk hud og på kvinner. Den spesifikke algoritmen hun jobbet med gjenkjente ikke hennes eget fjes før hun tok på seg en hvit maske. I 2017 fikk en kinesisk kvinne, bare kjent som Yan, refundert sin iPhone X fordi en kollega klarte å låse opp mobilen hennes med ansiktsgjenkjenning. I 2015 lanserte Google en tjeneste for merking av bilder der bilder av mennesker med mørk hud ble kategorisert som «gorilla». Googles’ midlertidige løsning på problemet var å fjerne kategorien «gorilla» inntil videre.
I alle disse tilfellene fungerte teknologien dårligere på ikke-hvitt utseende, blant annet fordi datasettet algoritmene var trent på manglet nok bilder av folk som ikke er hvite. Labeled Faces in the Wild er et av de mest brukte åpne datasettene for å trene og teste maskinlæring på ansiktsgjenkjenning. Dette er et sett med over 13 000 bilder av ansikter funnet på internett. Nevrale nettverk trent på dette datasettet fungerer aller best på å kjenne igjen ett spesifikt ansikt: George W. Bush. Dette er fordi mange av bildene ble samlet på nyhetssider i perioden 2001-2009 da Bush var president i USA.
«I dag er det ingen norske lover som spesifikt regulerer kunstig intelligens.»
Kunstig intelligens-algoritmer blir ikke laget i et vakuum. Ved å ta utgangspunkt i data som Labeled Faces in the Wild, blir underrepresentasjonen av minoriteter i nyhetsbildet videreført som diskriminering i spesifikke tjenester. Når teknologien i tillegg gjør det vanskelig å spore tilbake til akkurat hva i algoritmen som fører til diskriminerende resultat, er det desto viktigere at datasettet de er trent på er representativt før produktet slippes ut i samfunnet.
Det er ikke åpenbart hva som skal inkluderes i et datasett for å gjøre det representativt nok. Heller ikke hvem som skal bestemme det. I flere sammenhenger oppstår det også spørsmål om treningsdata bør reflektere samfunnet som det er, eller slik vi ønsker at det skal være. Skal en algoritme som brukes i en ansettelsesprosess lære at de fleste toppsjefer er hvite menn, eller skal den trenes på data der godene er jevnere fordelt på tvers av kjønn og etnisitet?
Det er ikke noe fasitsvar på slike spørsmål, men det som er klart, er at det må snakkes mer om problemstillinger knyttet til kunstig intelligens i den offentlige debatten. Det må diskuteres i kulturell og politisk sammenheng, før vi ser potensielle negative konsekvenser av dyplærte algoritmer også her hjemme.
Vi må prate om kunstig intelligens-etikk i norsk sammenheng
I dag er det ingen norske lover som spesifikt regulerer kunstig intelligens. Regjeringen la i begynnelsen av 2020 fram en nasjonal strategi med retningslinjer for utvikling av kunstig intelligens. Her nevnes det blant annet at algoritmer bør unngå diskriminering, men kravene er vage og kan ikke håndheves.
EU utvikler lover for regulering av kunstig intelligens fortløpende, som Norge også skal følge. Senest i april i år la EU fram et forslag til et lovverk som tidligst blir tatt i bruk i 2024. Lovverket har allerede blitt kritisert blant annet for ikke å ha strenge nok lover i forhold til ansiktsgjenkjenningsalgoritmer, og for å beskytte Big Tech: de fem store selskapene Google, Apple, Facebook, Amazon og Microsoft. Disse selskapene har i flere omganger blitt anklaget for etikk-washing, at de fremstår etiske utad, men følger sine egne etiske retningslinjer uten eksternt tilsyn. For selskaper som utvikler kunstig intelligens er det uten tvil en økonomisk fordel å hente på å kunne lage og følge sine egne regler. Et sett med representative treningsdata er for eksempel ofte dyrt.
Vi bør være på vakt for å verne om minoriteter når det gjelder kunstig intelligens, spesielt i det offentlige rom, også i Norge. Derfor er det viktig at diskusjoner om konsekvensene av maskinlæring kommer frem i søkelyset, og at konkrete krav til utvikling av kunstig intelligens blir adressert i politikken. Vi må etterlyse en offentlig debatt om kunstig intelligens, ikke bare styrt av økonomiske faktorer og ønsker om teknologisk utvikling, men med basis i grunnleggende verdier som antirasisme, mangfold og respekt.